xOne Cloud
SLAs
SLAs xOne
Service Level
Agreements
Esta página descreve os,
Service Level Agreements (SLAs)
do xOne Cloud,que estabelecem os
compromissos relacionados à
disponibilidade, desempenho e
suporte da plataforma.
SLAs (Service Level Agreements) xOne
Objetivo
Estabelecer os compromissos de atendimento e os prazos aplicáveis a incidentes, solicitações, melhorias e propostas de novas funcionalidades relacionadas ao produto xOne, com o objetivo de restaurar rapidamente a operação normal, minimizar impactos ao negócio do cliente e garantir níveis consistentes de qualidade e disponibilidade.
Além do tratamento de interrupções e falhas, o atendimento abrange dúvidas, pedidos de ajuda, solicitações de melhoria e propostas de novas funcionalidades, garantindo agilidade, rastreabilidade e transparência.
Escopo
Aplica-se a todos os incidentes e solicitações que afetam os serviços xOne contratados pelo cliente, incluindo a plataforma SaaS e os componentes do agent instalados no ambiente do cliente.
Princípios
- Foco na restauração rápida do serviço — priorizamos a retomada da operação normal com agilidade, mesmo antes da identificação da causa raiz, que é investigada e tratada na sequência para evitar recorrência.
- Classificação por impacto e urgência — os incidentes são avaliados conforme o grau de impacto no negócio e a urgência da resposta, direcionando os recursos de forma proporcional à criticidade.
- Comunicação clara e contínua — usuários e partes interessadas são mantidos informados durante todo o ciclo de vida do incidente, com transparência e alinhamento de expectativas.
- Melhoria contínua orientada por dados — métricas, indicadores de desempenho e feedback dos usuários são utilizados para aprimorar continuamente o processo de atendimento.
Janela de Atendimento
O suporte xOne opera em dias úteis, das 8h às 17h (horário de Brasília), exceto sábados, domingos e feriados nacionais.
Os tempos de resposta e resolução são contabilizados apenas durante a janela de atendimento. Chamados abertos fora desse período têm a contagem iniciada no início do próximo dia útil.
Os prazos são expressos em horas úteis. Considerando o expediente de 8 horas úteis por dia, a equivalência em dias úteis é indicada entre parênteses.
Abertura de Chamados
Os chamados devem ser registrados pelos canais oficiais de atendimento xOne (portal de suporte ou e-mail), com a descrição do problema, serviço afetado e horário de ocorrência. Quanto mais completas as informações, mais rápida a classificação e o início do atendimento. Consulte a página Atendimento e Suporte para os canais disponíveis.
Classificação de Prioridade
A prioridade de cada chamado é determinada pela combinação entre o impacto no negócio e a urgência da resposta necessária. A escala é única e aplica-se tanto à plataforma SaaS quanto ao agente.
| Prioridade | Nível | Descrição |
| P0 | Crítico | Serviço totalmente inutilizável ou risco ativo a dados/segurança, sem alternativa viável. Ex.: plataforma fora do ar, incidente de segurança em curso. |
| P1 | Alto | Função central degradada ou módulo importante indisponível, mas com operação ainda possível por meio de alternativa. Urgente, sem caracterizar parada total. |
| P2 | Médio | Funcionalidade com falha ou instabilidade, porém com alternativa viável e impacto contornável. Vários usuários afetados, nenhum totalmente bloqueado. |
| P3 | Baixo | Problema pontual, de baixo impacto e sem urgência. Afeta poucos usuários ou função secundária. Pode aguardar tratamento programado. |
| P4 | Planejado | Melhorias, ajustes cosméticos, dúvidas e solicitações sem impacto operacional. Tratado em ciclos de melhoria contínua. |
Critérios de Impacto
- Alto — afeta serviços críticos ou causa interrupção significativa da operação.
- Médio — afeta múltiplos usuários ou serviços importantes, com alternativas disponíveis.
- Baixo — afeta um número limitado de usuários ou serviços não críticos.
Critérios de Urgência
- Alta — requer ação imediata para evitar ou mitigar danos significativos.
- Média — exige atenção em curto prazo para evitar agravamento.
- Baixa — pode aguardar sem prejuízo imediato.
Prazos de Atendimento
Aplica-se a incidentes e solicitações da plataforma SaaS e do agent, sob uma única escala de prioridade.
| Prioridade | Tempo de Resposta | Tempo de Resolução |
| P0 – Crítico | 15 minutos | 4 horas úteis |
| P1 – Alt0 | 30 minutos | 8 horas úteis (1 dia útil) |
| P2 – Médio | 2 horas | 24 horas úteis (3 dias úteis) |
| P3 – Baixo | 4 horas | 72 horas úteis (9 dias úteis) |
| P4 – Planejado | 1 dia útil | Conforme planejamento |
Prazos contados dentro da janela de atendimento (dias úteis, 8h às 17h, horário de Brasília). A contagem não corre em finais de semana e feriados nacionais. O tempo de resolução pode ser suspenso enquanto o atendimento depender de retorno ou ação do cliente.
Escalonamento
Incidentes não resolvidos dentro do tempo previsto são escalados automaticamente para o próximo nível de suporte ou para a gestão. Chamados classificados como P0 acionam a gestão imediatamente, em paralelo ao atendimento técnico.
Níveis de Suporte
O atendimento é estruturado em níveis progressivos de especialização:
- Nível 1 (N1) — atendimento inicial, triagem, registro e resolução de solicitações simples ou recorrentes, com classificação e priorização adequadas.
- Nível 2 (N2) — diagnóstico técnico aprofundado, análise de logs e aplicação de procedimentos corretivos, com encaminhamento dos casos que exigem tratamento especializado.
- Nível 3 (N3) — resolução de problemas complexos ou críticos, implementação de soluções definitivas e proposição de melhorias estruturais.
Incidentes de Segurança
Incidentes com potencial impacto em segurança ou dados são tratados com prioridade máxima (P0/P1), seguindo processo dedicado de contenção, comunicação e análise pós-incidente, em conformidade com a LGPD e com as práticas de segurança da informação adotadas pela plataforma.
Registro e Documentação
Todos os incidentes são registrados com data e hora, descrição, classificação, ações tomadas, solução aplicada e tempo de resolução, assegurando rastreabilidade e histórico de atendimento.
Revisão
Este documento é revisado anualmente ou conforme necessidade estratégica, garantindo aderência às práticas de gestão de serviços de TI e aos compromissos assumidos com os clientes.
SLAs (Service Level Agreements) xOne
Objetivo
Estabelecer diretrizes técnicas para o gerenciamento de incidentes e solicitações nos serviços de tecnologia da informação, com o objetivo de restaurar rapidamente a operação normal, minimizar impactos negativos ao negócio e garantir níveis aceitáveis de qualidade e disponibilidade.
Este documento tem como finalidade definir o Acordo de Nível de Serviço (SLA) para o produto xOne, assegurando padrões claros de atendimento e prazos para incidentes, solicitações, melhorias e propostas de novas funcionalidades.
Além do tratamento de interrupções e falhas, inclui o atendimento eficiente a dúvidas, pedidos de ajuda, solicitações de melhoria e propostas de novas funcionalidades relacionadas a produtos ou serviços de TI, garantindo agilidade, rastreabilidade e alinhamento com os objetivos estratégicos da organização Arctica.
Escopo
Aplica-se a todos os incidentes que afetam os serviços de TI da organização Arctica, incluindo sistemas internos, serviços ao cliente e infraestrutura crítica. Abrange também todos os envolvidos na operação, suporte ou gestão desses serviços, como colaboradores, fornecedores e parceiros.
Princípios
- Foco na restauração rápida dos serviços
Priorizar a retomada da operação normal dos serviços de TI com agilidade, mesmo que a causa raiz ainda não tenha sido identificada. A investigação e resolução definitiva da origem do incidente serão conduzidas posteriormente pela função do processo de Gestão de Problemas.
- Classificação baseada em impacto e urgência
Os incidentes devem ser avaliados e tratados conforme o grau de impacto nos serviços e a urgência da resposta necessária, garantindo que os recursos sejam direcionados de forma eficiente e proporcional à criticidade da situação.
Clientes considerados estratégicos ou de alta relevância para o negócio devem receber prioridade no atendimento, considerando o potencial impacto comercial, reputacional ou operacional decorrente da indisponibilidade dos serviços.
- Comunicação clara e contínua
Manter os usuários e partes interessadas informados durante todo o ciclo de vida do incidente, por meio de canais adequados e linguagem acessível, promovendo transparência, confiança e alinhamento de expectativas.
A comunicação deve ser cuidadosamente alinhada em termos de discurso, tom e conteúdo com as áreas de gestão, comercial e de produtos, garantindo coerência institucional, preservação da imagem da organização e suporte às estratégias de relacionamento com o cliente.
- Melhoria contínua orientada por dados
Utilizar métricas, indicadores de desempenho e feedback dos usuários para revisar processos, identificar oportunidades de aprimoramento e fortalecer a maturidade da gestão de incidentes ao longo do tempo.
Controle de Incidentes de Segurança da Informação
Objetivo
Estabelecer diretrizes específicas para o tratamento de incidentes de segurança da informação, assegurando resposta rápida, contenção eficaz, comunicação adequada e registro completo, em conformidade com os princípios de confidencialidade, integridade e disponibilidade dos ativos da organização Arctica.
Escopo
Aplica-se a todos os incidentes classificados como relacionados à segurança da informação, incluindo, mas não se limitando a:
- Acessos não autorizados a sistemas ou dados
- Vazamento ou exposição indevida de informações sensíveis
- Ataques cibernéticos (ex: phishing, malware, ransomware)
- Vulnerabilidades críticas identificadas em sistemas
- Quebra de políticas de segurança por usuários internos ou terceiros
Classificação
Os incidentes de segurança devem ser classificados conforme os critérios gerais de impacto e urgência já definidos nesta política, com prioridade automática P1 para casos que envolvam:
- Vazamento de dados pessoais ou confidenciais
- Comprometimento severo de sistemas críticos (Lista no Anexo A)
- Ameaças ativas à integridade da infraestrutura
Tratamento
O tratamento de incidentes de segurança seguirá as etapas já previstas no processo geral de gestão de incidentes, com os seguintes cuidados adicionais:
Identificação e Registro
- O incidente deve ser registrado imediatamente no sistema oficial (Zoho Desk), com a marcação da categoria “Segurança”.
- Devem ser coletadas evidências técnicas (logs, capturas de tela, alertas de monitoramento).
Análise e Contenção
- A equipe de suporte deve acionar o responsável de segurança da informação (ou time SecOps) para análise técnica.
- Ações de contenção devem ser priorizadas para evitar propagação ou agravamento.
Comunicação
- As partes interessadas devem ser notificadas imediatamente, com alinhamento de discurso com as áreas de gestão e comunicação.
- Em casos de vazamento de dados, o DPO (Encarregado de Dados) deve ser envolvido.
Erradicação e Recuperação
- Após contenção, devem ser aplicadas correções definitivas (patches, reconfigurações, bloqueios).
- A restauração de serviços deve ser validada com foco na segurança.
Encerramento e Pós-Incidente
- O incidente deve ser documentado com causa raiz, impacto, ações tomadas e tempo de resposta.
- Deve ser realizada uma análise pós-incidente (post-mortem) com definição de ações corretivas e preventivas.
- Os aprendizados devem ser compartilhados com as equipes envolvidas.
Responsabilidades
Papel | Responsabilidade |
Service Desk [Suporte] | Registrar e classificar corretamente o incidente como “Segurança” |
Suporte Técnico N1, N2 e N3 | Executar contenção inicial e acionar especialistas |
Responsável de Segurança | Conduzir análise técnica, coordenar resposta e revisar documentação |
DPO | Avaliar obrigações legais e regulatórias em caso de vazamento |
Gestão | Apoiar comunicação e decisões estratégicas |
Norma de Gestão de Incidentes e SLAs de atendimento
- Dado o alto grau de complexidade do nosso produto digital — que envolve parametrização, configuração, novas funcionalidades, requisitos não funcionais, ajustes de arquitetura e ambiente — é essencial que a classificação de incidentes de defeitos (erros) na gestão de problemas ITIL 4 seja feita de forma mais granular e estratégica. Abaixo está uma proposta detalhada de modelo de classificação, alinhada com a prática ITIL e adaptada à nossa realidade.
Termos e Definições
- Incidente: Interrupção ou degradação não planejada de um serviço de TI.
- Urgência: Tempo aceitável para resolução do incidente.
- Impacto: Grau de efeito no negócio causado pelo incidente.
- Prioridade: Determinada pela combinação entre impacto e urgência.
- Service Desk: Ponto único de contato entre usuários e o provedor de serviços de TI. Plataforma Zoho Desk.
Classificação de Incidentes:
- Impacto: Alto, Médio, Baixo
- Urgência: Imediata, Alta, Média, Baixa
- Prioridade: Determinada pela matriz de impacto x urgência
Responsabilidades:
- Usuários: Registrar incidentes via portal, telefone ou e-mail e deve reportar incidentes com informações completas.
- Service Desk: Classificar, registrar, priorizar, resolver, escalar e acompanhar incidentes.
- Grupos de Suporte: Resolver incidentes conforme prioridade e SLA.
- Gestor de Incidentes: Monitorar o processo, desempenho, garantir conformidade com SLAs, reportar métricas.
- Gestor de Problemas: Investigar causas raiz de incidentes recorrentes e propor ações corretivas.
Matriz de Classificação de Incidentes: Impacto x Urgência
Impacto / Urgência | Baixa Urgência | Média Urgência | Alta Urgência |
Baixo Impacto | Prioridade 4 – Monitorar | Prioridade 3 – Agendar atendimento | Prioridade 2 – Atender em breve |
Médio Impacto | Prioridade 3 – Agendar atendimento | Prioridade 2 – Atender em breve | Prioridade 1 – Atender imediatamente |
Alto Impacto | Prioridade 2 – Atender em breve | Prioridade 1 – Atender imediatamente | Prioridade 1 – Atender imediatamente |
Critérios de Impacto
- Baixo: afeta um número limitado de usuários ou serviços não críticos.
- Médio: afeta múltiplos usuários ou serviços importantes, mas com alternativas disponíveis.
- Alto: afeta serviços críticos, clientes estratégicos ou causa interrupção significativa no negócio.
Critérios de Urgência
- Baixa: pode aguardar sem prejuízo imediato; impacto tolerável.
- Média: exige atenção em curto prazo para evitar agravamento.
- Alta: requer ação imediata para evitar ou mitigar danos significativos.
Classificação por Tipo de Defeito
Ajuda a entender a natureza técnica do problema:
Tipo de Defeito | Descrição |
Parametrização | Erros em regras de negócio configuráveis, como fluxos, permissões, etc. |
Configuração | Falhas em arquivos, variáveis de ambiente, integrações, etc. |
Funcionalidade | Bugs em funcionalidades existentes ou falhas em novas entregas. |
Requisito Não Funcional | Problemas de desempenho, escalabilidade, segurança, etc. |
Arquitetura / Infraestrutura | Falhas em componentes técnicos como APIs, banco de dados, rede, etc. |
Ambiente | Problemas em ambientes de homologação, produção, testes, Sass – software como serviço, etc. |
Classificação por Impacto
Avalia o quanto o defeito afeta o negócio:
Nível | Critério |
Alto | Interrupção total de serviço crítico, perda de dados, impacto em clientes. |
Médio | Funcionalidade degradada, mas com alternativas viáveis. |
Baixo | Problemas menores, sem impacto direto na operação. |
Classificação por Urgência
Define o tempo de resposta necessário:
Nível | Critério |
Alta | Precisa ser resolvido imediatamente para evitar paralisações. |
Média | Pode aguardar, mas deve ser tratado em breve. |
Baixa | Pode ser resolvido em ciclos de melhoria contínua. |
Tendência de Recorrência
Problemas reincidentes ou com potencial de repetição devem ser priorizados, mesmo que o impacto ou
Classificação por Origem
Ajuda na análise de causa raiz:
Origem Possível | Exemplos |
Erro de Desenvolvimento | Código mal implementado, testes insuficientes. |
Erro de Integração | APIs externas, falhas de comunicação entre sistemas. |
Erro de Implantação | Deploys mal executados, versões incompatíveis. |
Erro de Infraestrutura | Falhas em servidores, rede, banco de dados. |
Erro de Uso / Treinamento | Falta de conhecimento do usuário, má configuração manual. |
Sugestão de Tabela de Classificação de Incidentes de Defeitos
ID | Tipo de Defeito | Impacto | Urgência | Tendência | Origem | Prioridade |
001 | Funcionalidade | Alto | Alta | Sim | Dev | Crítica |
002 | Parametrização | Médio | Média | Não | Uso | Média |
003 | Arquitetura | Alto | Alta | Sim | Infra | Crítica |
004 | Requisito Não Funcional | Baixo | Baixa | Sim | DevOps | Baixa |
Fluxograma de Atendimento por Impacto x Urgência (Prioridades P1 a P5)
Recebimento do Incidente
- Registrar o incidente no sistema.
- Coletar informações: serviço afetado, número de usuários, cliente envolvido, sintomas, horário de ocorrência.
Classificação Inicial
- Impacto:
- Baixo – afeta poucos usuários ou serviços não críticos.
- Médio – afeta múltiplos usuários ou serviços importantes.
- Alto – afeta serviços críticos, clientes estratégicos ou causa interrupção significativa.
- Urgência:
- Baixa – pode aguardar sem prejuízo imediato.
- Média – exige atenção em curto prazo.
- Alta – requer ação imediata.
Determinação da Prioridade
Impacto | Urgência | Prioridade | Tempo de Resposta |
Baixo | Baixa | P5 | Até 72h |
Baixo | Média | P4 | Até 48h |
Baixo | Alta | P3 | Até 24h |
Médio | Baixa | P4 | Até 48h |
Médio | Média | P3 | Até 24h |
Médio | Alta | P2 | Até 8h |
Alto | Qualquer | P1 | Imediato |
Observação: Incidentes que envolvem clientes estratégicos ou serviços críticos devem ser classificados como Alto Impacto, garantindo prioridade P1, independentemente da urgência.
Ação de Atendimento
- Designar equipe responsável.
- Iniciar tratativa conforme prioridade.
- Registrar ações e atualizações.
Comunicação
- Informar usuários e partes interessadas sobre status e previsão.
- Alinhar discurso com áreas de gestão, comercial e produtos.
Encerramento
- Validar restauração do serviço.
- Registrar causa e ações.
- Encaminhar para Gestão de Problemas, se necessário.
Revisão e Melhoria
- Avaliar métricas e feedback.
- Promover melhorias no processo.
Prazos de Atendimento (SLAs de atendimento)
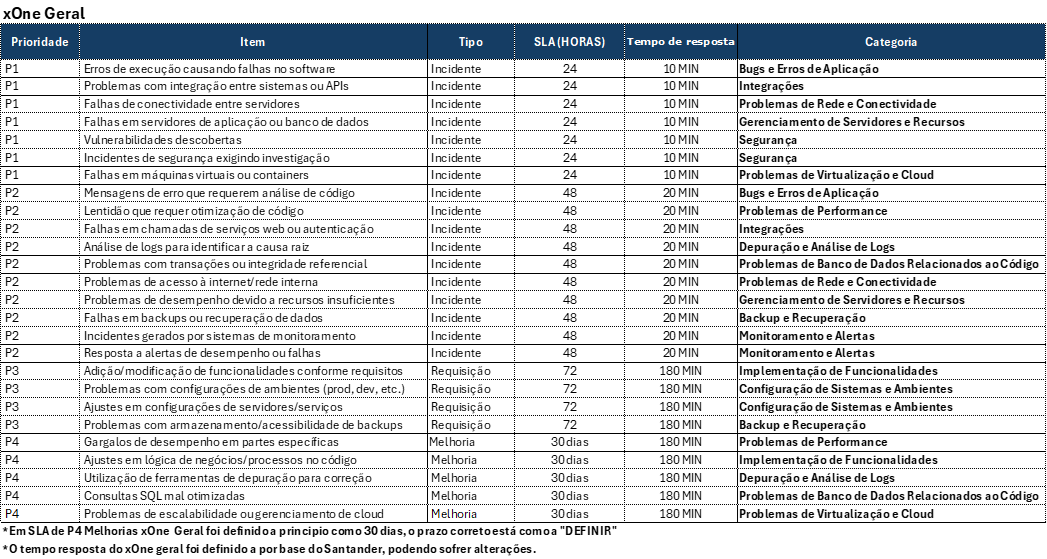
Solicitações em geral
Prioridade | Tempo de Resposta | Tempo de Resolução |
Crítica | 15 minutos | 4 horas |
Alta | 30 minutos | 8 horas |
Média | 2 horas | 24 horas |
Baixa | 4 horas | 72 horas |
Escalonamento
Incidentes não resolvidos dentro do tempo previsto devem ser escalados automaticamente para o próximo nível de suporte ou gestão.
Registro e Documentação
Todos os incidentes devem ser registrados com:
- Data e hora
- Descrição
- Classificação
- Ações tomadas
- Solução aplicada
- Tempo de resolução
Auditoria e Revisão
- Esta norma será revisada anualmente ou conforme necessidade estratégica. Auditorias internas serão realizadas para verificar conformidade e eficácia do processo.
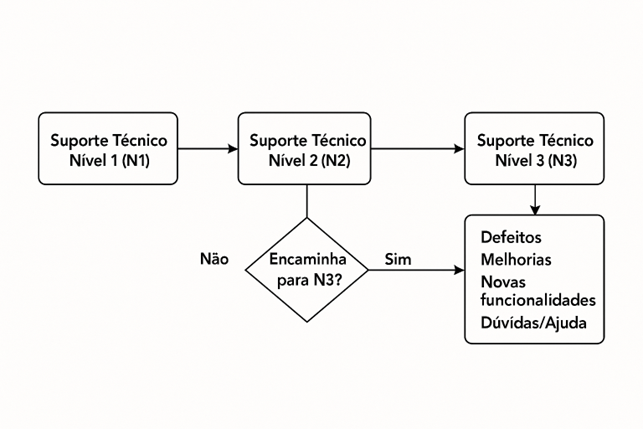
Suporte Técnico Nível 1 (N1)
Responsável pelo atendimento inicial das solicitações, realizando triagem, registro e resolução de problemas simples ou recorrentes. Além disso, classifica e prioriza as solicitações conforme criticidade e impacto, garantindo que os casos sejam escalonados corretamente para os níveis superiores quando necessário. Atua também na coleta de informações básicas sobre o incidente ou requisição, mantendo comunicação clara com o usuário. Consulta a base de defeitos conhecidos KBE registrado no Zoho Desk, para responder prontamente em função da solicitação já ter solução conhecida.
Suporte Técnico Nível 2 (N2)
Executa análises mais detalhadas, tratando incidentes que exigem conhecimento técnico intermediário. Realiza diagnósticos aprofundados, consulta logs e aplica procedimentos corretivos. Também é responsável por validar soluções propostas pelo N1 e fornecer orientações para evitar recorrência. Consulta a base de defeitos conhecidos KBE registrado no Zoho Desk, para responder prontamente em função da solicitação já ter solução conhecida.
Quando não é possível resolver, encaminha o chamado para N3 (Gerente de Projeto de Produto), classificando e direcionando conforme a natureza da solicitação:
- Defeitos (bugs ou falhas identificadas)
- Melhorias (ajustes em processos ou sistemas existentes)
- Novas funcionalidades (demandas de evolução)
- Dúvidas/Ajuda (consultas técnicas ou orientações específicas)
Suporte Técnico Nível 3 (N3)
Atua na resolução de problemas complexos ou críticos que demandam conhecimento avançado e integração com áreas de desenvolvimento ou gestão de projetos. É responsável por tratar solicitações classificadas pelo N2, como defeitos, melhorias, novas funcionalidades e dúvidas/ajudas, e ajustar a classificação de forma mais precisa se for o caso, garantindo análise profunda e implementação de soluções definitivas. Além disso, pode propor melhorias estruturais e otimizações para assegurar estabilidade e desempenho dos sistemas.
Como parte da estratégia de melhoria contínua, nosso objetivo é maximizar a resolução das solicitações nos níveis N1 e N2, garantindo agilidade e eficiência no atendimento. Para isso, serão implementadas ações que incluem:
- Capacitação das equipes de N1 e N2 para ampliar o conhecimento técnico e reduzir a necessidade de escalonamento.
- Otimização de processos e ferramentas para permitir diagnósticos mais rápidos e precisos nos níveis iniciais.
- Classificação e priorização inteligente das solicitações, assegurando que apenas casos realmente complexos ou críticos sejam direcionados ao N3.
- Monitoramento contínuo de indicadores para identificar oportunidades de melhoria e reduzir sobrecarga no N3.
Essa abordagem visa evitar gargalos no nível N3, permitindo que este se concentre em demandas estratégicas, como defeitos críticos, melhorias estruturais e novas funcionalidades, enquanto os níveis N1 e N2 absorvem o maior volume de solicitações com qualidade e rapidez.
As equipes de N1 e N2 devem ser continuamente capacitadas por meio dos treinamentos disponíveis e, quando pertinente, por meio de trocas técnicas com o time de N3. O conhecimento quando se tratar de de defeitos com solução conhecida deve ser registrado na base de defeitos conhecidos KBE.
Ferramentas de Apoio
- Sistema de ITSM (Zoho Desk, Jira)
- Monitoramento proativo (Zoho Desk e Splunk)
- Base de conhecimento para resolução rápida (SharePoint)
Governança e Auditoria
- Auditorias anuais para verificar conformidade com o processo.
- Relatórios para comitê de TI com análise de tendências e ações corretivas.
Referências Normativas
- ITIL 4 – Práticas de Gerenciamento de Incidentes
- ISO/IEC 20000 – Gestão de Serviços de TI
- Política de Segurança da Informação
- Acordos de Nível de Serviço (SLAs), alinhados e registrados neste documento.
Histórico de Revisões dos documentos
- Este documento será revisado anualmente ou conforme necessidade estratégica.
Atualização e Revisão
- A lista de sistemas críticos deve ser revisada semestralmente ou sempre que houver alterações significativas na arquitetura, nos contratos ou nos riscos operacionais.
- A inclusão ou exclusão de sistemas deve ser aprovada pela Operações e Suporte e Segurança da Informação.
Histórico de Revisões
| Versão | Data | Responsável | Descrição da Alteração |
| 1.0 | 27/01/2022 | Operações e Suporte | Emissão inicial do documento |
| 2.0 | 15/01/2023 | Operações e Suporte | Atualização e ajustes |
| 3.0 | 17/01/2024 | Operações e Suporte | Atualização e ajustes |
| 4.0 | 20/01/2025 | Operações e Suporte | Atualização e ajustes |
Aprovação
| Nome do Responsável | Cargo | Status | Data |
Carlos Alberto Figueiredo
| Coordenador de Operações e Suporte Técnico
| Revisão e ajustes do documento e aprovação | 20/01/2025 |